在工業4.0與智能制造浪潮下,數字化工廠已成為制造業轉型升級的核心路徑。而數據處理服務作為工廠數字化的“中樞神經”,其規劃質量直接決定了數字化建設的成敗。一個科學、系統、前瞻的數據處理服務規劃,能夠將海量、異構的工業數據轉化為驅動生產效率、產品質量與決策優化的核心資產。
一、規劃前期:明確目標與評估現狀
規劃之初需確立清晰的戰略目標,例如:實現生產全流程可視化、構建預測性維護能力、優化供應鏈協同或支持個性化定制生產。必須對工廠現狀進行全面“數據體檢”:
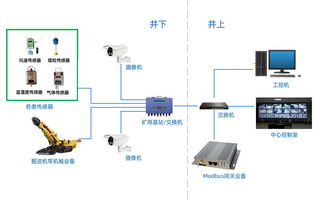
- 數據源盤點:梳理各類設備(PLC、CNC、機器人)、傳感器、MES/ERP/WMS等信息系統、質量檢測設備及外部供應鏈數據。
- 數據現狀評估:分析數據格式(時序數據、圖像、日志)、規模、生成頻率、現有存儲方式(本地、孤島化)及數據質量(完整性、準確性、一致性)。
- 基礎設施與能力評估:審視現有網絡(OT/IT網絡融合情況)、計算資源、存儲架構及團隊的數據分析技能。
二、架構設計:構建分層解耦的數據處理體系
核心是設計一個彈性、可擴展的數據處理服務架構,通常采用分層模型:
- 邊緣層:在靠近設備端部署邊緣計算節點,進行數據實時采集、協議解析、高速時序數據處理、邊緣AI推理及本地實時控制,實現數據輕量化和低延時響應。
- 平臺層(核心):構建工廠級數據平臺或工業數據湖/倉。
- 接入與集成:通過工業網關、API等方式統一接入邊緣層及各系統數據。
- 存儲與治理:設計冷熱溫數據分層存儲策略;建立數據標準、元數據管理、主數據管理及數據質量監控體系。
- 處理與分析:部署流處理引擎(如Flink)處理實時數據流,批處理引擎(如Spark)處理歷史數據;提供數據清洗、轉換、建模工具及AI算法框架。
- 應用層:基于平臺層的數據服務能力,構建面向業務場景的數據產品與應用,如設備健康度看板、能耗優化分析、生產質量根因分析、數字孿生仿真等。
三、關鍵技術服務選型與實施要點
- 數據連接與采集服務:選用支持OPC UA、MQTT、Modbus等主流工業協議的工具,確保全要素、全鏈路數據可達。
- 數據存儲服務:針對時序數據(InfluxDB、TDengine)、關系數據、文檔數據及海量非結構化數據(如圖像、視頻),選擇合適的數據庫與數據湖存儲方案。
- 數據處理與分析服務:
- 實時處理:用于監控報警、實時OEE計算。
- 批處理與數據挖掘:用于歷史趨勢分析、工藝優化。
- AI/ML服務:集成或開發用于缺陷檢測、預測性維護、智能排程的模型。
- 數據安全與合規服務:貫穿始終,建立從邊緣到云的數據加密、訪問控制、安全審計及工業數據分類分級保護機制,符合國家及行業法規。
四、運營與治理體系規劃
規劃必須包含可持續的運營藍圖:
- 組織與團隊:建立包含數據工程師、數據科學家、領域專家的跨職能數據團隊,明確與OT、IT及業務部門的協作流程。
- 治理流程:制定數據標準管理、數據生命周期管理、數據質量持續改進及數據資產目錄發布的制度化流程。
- 平臺運營:設計監控體系,保障數據處理管道SLA;建立成本優化機制(如計算資源彈性伸縮);規劃平臺的持續迭代與升級路徑。
五、分階段實施路線圖
建議采用“整體規劃,分步實施,價值驅動”的策略:
- 第一階段(試點筑基):聚焦關鍵產線或核心設備,完成數據采集與平臺基礎部署,實現1-2個高價值可視化場景。
- 第二階段(擴展集成):橫向擴展數據采集范圍,深化數據治理,開發預測性分析等高級應用,實現部門級協同。
- 第三階段(全面智能):實現全廠數據融合,支持基于數據的全流程自主優化與創新業務模式,形成數據驅動文化。
數字化工廠的數據處理服務規劃是一項系統性工程,需緊密圍繞業務價值,以架構為骨、數據為血、技術為肌、治理為魂,通過循序漸進的實施,最終將數據流轉化為驅動工廠智能化、柔性化、綠色化發展的強大價值流。